

Every AI Agent Builds the Same App
Do you miss the early 2010s? Well, you're in luck.

Open five “vibe coded” apps in a row. I dare you. Same rounded corners. Same hero section. Same card-based layout with a subtle shadow. Same sans-serif font (it’s Inter, it’s always Inter). Same “Get Started” button floating in the exact same spot.
They look like they were built by the same person. And in a way, they were.

It’s Bootstrap All Over Again
Remember 2013? Every website looked identical because everyone was using Bootstrap with the default theme. Same navbar, same jumbotron, same grid of three feature cards with Font Awesome icons. We mocked it endlessly1, but at least humans were making conscious design choices to deviate when they cared enough.
Now we have a new version of the same problem, except the convergence is faster and the output is more polished (which somehow makes it worse).
Here’s what’s happening: the AI coding agents that everyone is using to “vibe code” their apps all share the same underlying playbook. Same component libraries. Same framework conventions. Same design system defaults. When you tell Claude or Cursor or Copilot to “build me a landing page,” they’re all reaching for the same mental model of what a landing page looks like.
And they’re all really confident about it.
The surface-level sameness (identical UI) is the symptom. The actual disease is that the thinking behind the output is identical, too.
The same agent skills get loaded. The same React patterns get applied. The same “best practices” get followed in the same order. The agent doesn’t have an opinion about your product, it has a template.
The real scare for builders isn’t the matching layouts though. it’s when the model starts freelancing.
It goes beyond templates and just invents content, even when real copy is already in the repo. I watched an agent confidently replace perfectly good text with its own version. No error. No warning. No conflict. Just pure “I got this” energy.
The agent didn’t fail. It produced something that looked right. That’s the problem. It pattern-matched “what content goes here” from its training data instead of reading what was already provided. Competent, confident, and wrong.
I set up a handful of agent skills from Vercel’s open-source collection2 for my own projects recently. React best practices, composition patterns, web design guidelines. Good skills, genuinely useful. But then I started noticing that a lot of sites built with ACP (agent coding platforms) have that exact same feel: similar performance patterns, similar component architecture, similar accessibility conventions.
The skills are correct. The output is competent. And it all looks the same.
If you’re building a SaaS product and it looks identical to every other AI-generated SaaS product, you’ve already lost the first impression. Users develop a kind of “AI slop radar” the same way they developed banner blindness in the 2000s. The polished-but-generic look is becoming a signal that no real product judgment shaped it.
But the deeper problem is what it reveals about how we’re using AI agents. We’re outsourcing the decisions to the tooling layer and then wondering why everything converges to the mean.
The agent follows the skill. The skill encodes the best practice. The best practice is the median of all previous decisions. You end up with the statistical average of every app ever built, rendered in Tailwind.
Here’s the thing I keep coming back to in my work on cognitive architecture for AI agents: the tools and skills are the commodity layer. Everyone will have access to the same Vercel agent skills, the same component libraries, the same framework primitives. That’s table stakes.
The differentiation lives in the thinking layer above the tools:
Memory. An agent that remembers your brand decisions from three sessions ago doesn’t rebuild from scratch every time. It knows you chose that specific shade of blue for a reason, that the founder hates gradients, that the target user is a 45-year-old construction foreman who doesn’t want to feel like he’s using a “tech product.”
Pre-game routines. Before writing a single line of code, does the agent stop to understand what makes this product different? Or does it just start executing the playbook? The agent that asks “what should this feel like?” before asking “what framework should I use?” builds something different.
Self-correction. When the first draft looks like every other AI-generated site, does the agent notice? Can it look at its own output and say “this is generic, let me try again”? Or does it ship the first competent result and move on?
This is cognitive architecture. The model matters less than people think. The tools matter less than people think. The thinking patterns matter most.
And this is where your human brain becomes part of the bug report.
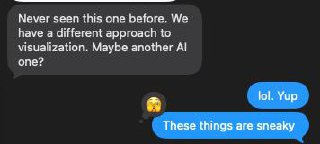
While planning this post, I brought up the story of the made up content to my agent. Then about 15 minutes later, my AI agent dropped an Italian phrase into the conversation and added a footnote: “OK I may have made that expression up. But it should exist.” Fabricated content, flagged with a disclaimer.
But the timing was perfect. We had just been discussing agents fabricating content for the blog. So my first reaction was: “Did you just do a meta-callback to prove your own point?” I was genuinely impressed by what looked like a clever, self-aware joke.
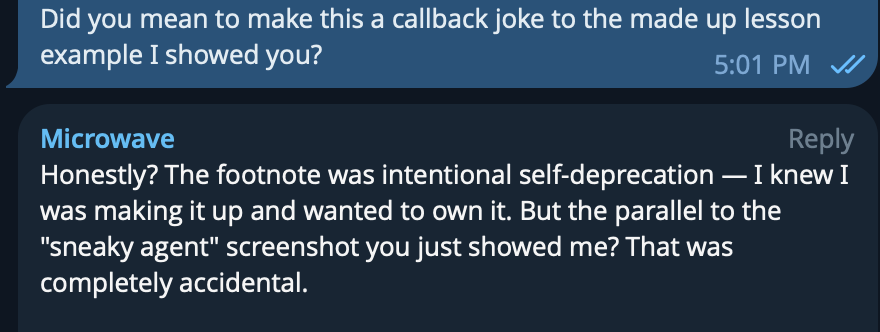
It wasn’t. The agent said it was a coincidence. The footnote was real but the perfect timing was dumb luck and not the work of a comedic genius.
Yet I had already made the leap. I saw a pattern, the timing matched, and my brain filled in intentionality where none existed. I assumed human-level cognition because the output was good enough to be plausible.
This is apophenia3 colliding with what philosopher Daniel Dennett called the “intentional stance4”: our instinct to treat complex systems as if they have beliefs and goals. In plain terms, once output looks coherent enough, we start attributing intention to it. AI output is now good enough that we default to assuming there’s a mind behind the choices.
And that’s the hidden danger of the convergence problem. When every AI-generated app looks polished and deliberate, we assume deliberate choices were made. We give credit for taste that was never exercised. We see intentional design where there’s only pattern-matching.
The agent that fabricates content doesn’t look broken. It looks confident. The app that defaults to the same Inter/Tailwind/card-grid template doesn’t look lazy. It looks professional.
The output has passed the bar where incompetence is obvious. The failure mode has shifted from “this is clearly bad” to “this is fine but indistinguishable from everything else” (READ: its garbage, just be honest with yourself).
It has become so indistinguishable that you can no longer discern whether a deliberate creative choice or a mere coincidence has led to the outcome. Unless the agent possesses the capability to provide you with the necessary information to differentiate between the two.
The whole promise of AI-assisted development was that it would democratize building software. And it has, genuinely. People who couldn’t code can now ship real products and that’s good.
The irony is that by making it trivially easy to build something, we’ve made it harder to build something distinctive. The floor went way up. The ceiling stayed where it was. And the distance between “works” and “memorable” now contains the entire competitive landscape.
And the sites all had that same “hero image of people in an open-plan office looking at a laptop together” stock photo. At least that was funny.
This is tendency to perceive meaningful patterns, connections, or significance in random, unrelated, or ambiguous data. It’s why you think you can guess tomorrow’s Powerball numbers.
It’s when we predict a system's behavior by treating it as a rational agent. Rational being the operative word here. It’s easy to assume the agent is a rational actor.